
Myles Suer, writing for CIO magazine, states that IT leaders “need to focus upon things which provide value to customers”. These things include the time and effort spent on reducing business friction. When it comes to business priorities, nothing speaks louder than having available and reliable IT services that support business outcomes.
Of course, struggles to align IT with business needs are well documented. But if you take a different view—a view of how you handle incidents, changes, and requests—you’ll get a clearer picture on priorities from both sides.
To determine whether something is a value-add, you must define, prioritize, and measure the activities that do and don’t support such efforts.
Prioritization is vital for IT and business needs: it tells us the relative importance of an incident, so you’ll know how quickly to respond to address it, and how long that effort might take. In ITSM, the most common prioritization incident priority matrix model involves understanding impact and urgency. How IT responds, handles, and resolves any request or issue to the business and/or customers depends upon what both parties think about impact and urgency.
What is the Impact-Urgency-Priority Matrix?
The Impact-Urgency-Priority Matrix is a tool you can use to assess tasks, issues, and potential actions and prioritize them according to their impacts, or consequences, and their time-sensitive importance, or urgency.
As an IT Service Management (ITSM) and business tool, the Impact-Urgency-Priority Matrix is invaluable in deciding what needs immediate action and how to address all issues in an orderly and optimized fashion. The Matrix ensures nothing falls through the cracks and that critical issues get resolved with speed—all with time and budget efficiency in mind.
Though you can boil down impacts, urgencies, and priorities into a simple mathematical equation, this is not recommended. Instead, look at impact, urgency, and priority as making decisions about relative importance and context. These are items only you and your company can define.
Let’s take a look at each of these factors and how context and relativity support them.
Take IT Service Management to the next level with BMC Helix ITSM. ›
Impact
In incident management, impact is defined as the effect an incident, problem, or change may have on your business processes.
This could be positive, such as improved return on investment or higher customer satisfaction from providing a new feature or product improvement. Or it could be negative, such as the loss of revenue, time, or customers following IT service downtime or poor performance.
Defining the levels of impact
Impact is not usually expressed in absolute terms, but rather as a range or degree that is subject to the interpretation within your company’s context. This range might include:
- Number of customers/users affected
- Amount of lost revenue or incurred costs
- Number of IT systems, services, or elements involved
A variety of terms can help classify the impact, or effect, of an incident. Here’s an example of an impact scale, from high to low, based on the number of users affected:
- High – Extensive or widespread, affects all users. For example, your service is hacked, leading to downtime and potential data breach.
- Medium – Moderate or multi-user. For example, a software upgrade for a client may lead to their system going down, affecting one or a few clients and all of their users.
- Low – Individual or single user. For example, a single user may find themselves locked out of accessing a service until a technician can step in and fix the issue.
All involved parties must share the same understanding of the scale used. Clear, common understanding of the impact scale is the first step in effective prioritizing.
Urgency
Urgency is about time and the speed at which the business or customer expects and needs an issue addressed. Restoring service to normal operation may need to be done in minutes, whereas the urgent development and delivering of a new or updated service or product may be measured in weeks or months.
The longer the acceptable wait time, the lower the urgency. Anything that significantly affects your business from an operational, compliance, or financial perspective is generally more pressing than impacts on other perspectives. For example, an outage to a cloud service covering a whole region requires a shorter response and resolution time than a VIP’s request, because it is a more urgent issue.
What are the scales of urgency?
Like impact, urgency scales depend on your business context, needs, and risks. Common scales used in defining urgency are:
- High – The failure of a mission-critical service may stop a business from operating, making it an urgent issue to fix.
- Medium – These issues are annoying and frustrating, but don’t put an immediate stop to client operations or generally don’t lead to immediate and costly losses.
- Low – These issues cause waste or loss of efficiency, yet are not particularly disruptive—unless they are left to fester and grow.
Priority
In incident management, priority is the intersection of impact and urgency. Considering the impact and urgency matrix offers your company a clearer understanding of what is more important when it comes to a change: a request, or an incident.
Remember that priority is relative. It defines what actions to take, but these are never set in stone—they can vary as the context shifts.
Correlating impact and urgency can be easily done in a simple incident priority matrix, which can be hardcoded into your ITSM solutions. This makes for an easy way to determine service levels and track performance measures when treating incidents, problems, requests, or changes.
How to set your priority levels
Priority scales are set by combining impact and urgency. They are usually defined as:
- High – Items that are high-impact and high-urgency earn the highest priority level. These are drop-everything-and-fix-this-now issues.
- Medium – Items that are high impact with moderate urgency should be addressed relatively quickly. Items that are highly urgent, but have a low impact might benefit from a quick fix.
- Low – These items need to be scheduled, but don’t require instant attention or an all-hands effort.
Some models use five priority levels to fine-tune how to respond and spend resources, assigning a numerical priority value to each level.
- Critical – Urgent and business-critical issues that require a crisis-level response.
- High – While the need isn’t immediate, these tasks are still important and may contribute to significant goals.
- Moderate – These tasks must be prioritized against other issues, with a decision about when and how to address them efficiently.
- Low – Issues and tasks that are part of the routine and need to be done, but won’t have a significant impact on your progress or timelines.
- Lowest – These need to be evaluated as to whether they are worth doing or whether they can be placed on a backlog/as-resources-allow status.
Impact-Urgency-Priority Matrix examples
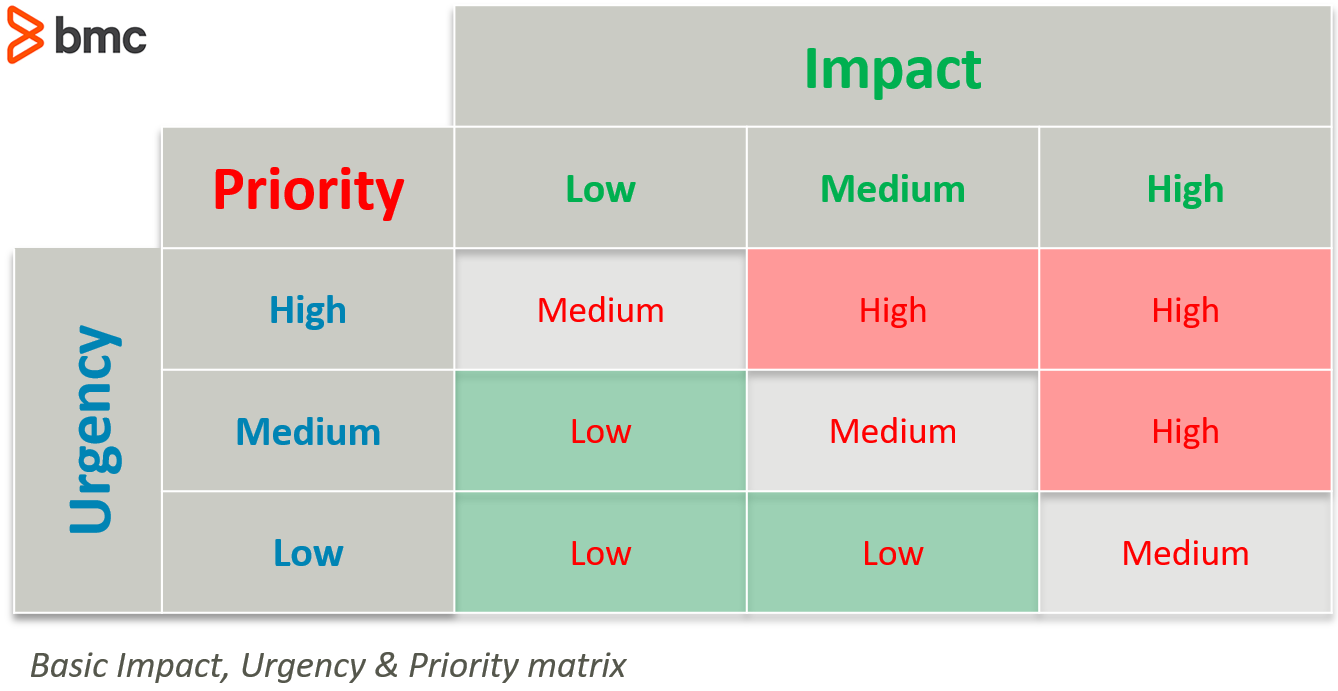
Here’s an example of a basic Impact-Urgency-Priority Matrix. Anything that has both high impact and high urgency gets the highest priority, while low impact and low urgency results in the lowest priority.
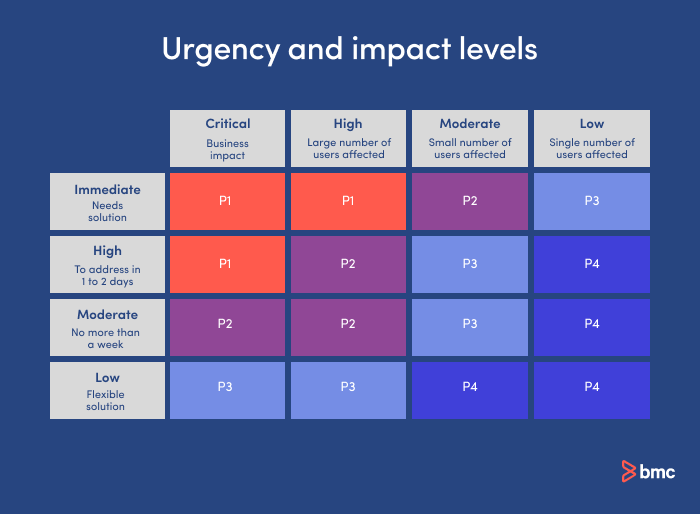
With more detail and nuance, a matrix that includes five levels of impact and five levels of urgency can help you fine-tune your priorities and resource allocation.
Best practices for determining impact, urgency, and priority
No priority matrix is a one-size-fits-all framework. You’ll want to define your levels of urgency, impact, and priority alongside key stakeholders, then continually review your definitions as you encounter various scenarios. What might be a high priority to the business might be much lower in the eyes of a third-party vendor; therefore, alignment across all agreements and contracts is critical.
When users and support teams have the freedom to dictate the impact, urgency, and priority of their submitted issue, you’ll likely see a confusion of priority vs. urgency. This freedom might be necessary for support teams to give situational context, but it can have a bad effect: most users will likely choose the highest level of priority even for mundane matters with low urgency, like obtaining a gaming mouse for use even though their work involves spreadsheets.
Conversely, support teams are likely to choose lower levels due to their perception of effort involved or performance rating model applied (i.e., not wanting to restrict themselves to shorter resolution timelines that they are unlikely to meet.)
To address this, you must use policy to clearly define what constitutes urgency vs. priority and provide relevant examples to guide all teams involved toward a common picture and effective collaboration. Then, of course, you’ll have maintained focus on the particular components, situations, and requests that offer value to your customers.






