
You’ve heard the saying “time is money”? Well nothing is closer to the truth than when looking at the impacts of unplanned downtime on your mainframe budget, business initiatives and a potentially negative experience for your customers.
A 2019 Forrester survey of 100 US IT groups found that the average cost of a minute of an unplanned “outage” was $9,108. Simple math would result in almost $1.4 Million lost if an enterprise experienced ten outages throughout the year at 15 min each. This doesn’t even factor in operational resilience fines levied to banks from the UK-based Financial Conduct Authority (FCA) for the inability to maintain the safety and soundness of their infrastructure and, by extension, their customer’s data, and funds.
Compounding these risks is the newer workforce charged with managing the platform. BMC’s 15th Annual Mainframe Survey showed 43 percent of respondents had five years or less experience on the mainframe and those with greater than ten years of experience had decreased by 19 percent. This newer workforce needs to receive proactive alerting when an event occurs that an experienced professional would normally catch on their own.
The Anatomy of a Storage Leak
Let’s take a look at one of these potentially crippling events in action, working backwards from the time of a Db2 subsystem restart.
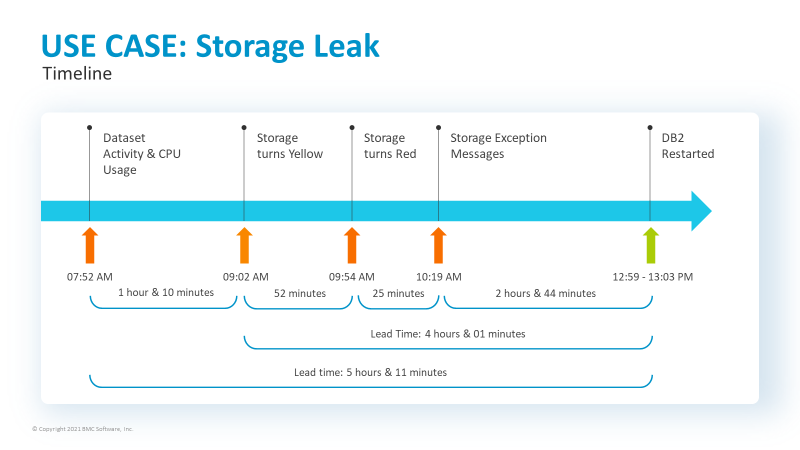
- 12:59 – 1:03pm: Restart of DB2 subsystem
- 10:19am: A storage exception message was provided.
- 9:54am: Storage issue detected
- 9:02am: Potential storage issue detected
- 7:52am: High CPU usage and dataset activity detected
If one was given proactive notification at the time of the high CPU usage, five hours and 11 minutes before the Db2 subsystem restart, sufficient actions could have been taken to mitigate this four-minute outage, potentially over $36,000 in loses and additional risks avoided.
BMC AMI Ops Insight: The Power of AI and Machine Learning at Work
Leveraging AI and machine learning (ML) is vital to catching those early indicators of an event before they become a full-blown outage. Take BMC AMI Ops Insight’s multi-variant approach with the ability to look at multiple KPIs at once and cross-reference multiple groups simultaneously to detect issues earlier and with more accuracy. And while this level of observability seems complex, it’s surprisingly simple to implement.
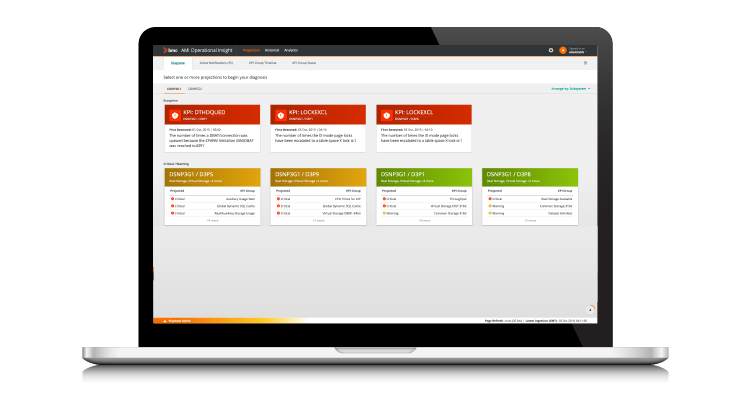
By collecting four to six weeks of historic SMF data, BMC AMI Ops Insight creates a model of what “goodness” looks like and creates a baseline for LPARs to be measured against. Once this normal working model is created, the solution creates hundreds of scores a minute and triggers an alert when a rogue application creates an abnormal event. These alerts are then collated into a simple to use color-coded dashboard view which provides greater detail on the event.
By prioritizing the more critical issues in red, moderate in yellow and normal events in green, your newer workforce will understand which events to tackle first to ensure uptime is maintained and risks avoided – achieving greater operational resilience.
These postings are my own and do not necessarily represent BMC's position, strategies, or opinion.
See an error or have a suggestion? Please let us know by emailing blogs@bmc.com.





