
You are probably familiar with Nvidia as they have been developing graphics chips for laptops and desktops for many years now. But the company has found a new application for its graphic processing units (GPUs): machine learning. It is called CUDA.
Nvidia says:
“CUDA® is a parallel computing platform and programming model invented by NVIDIA. It enables dramatic increases in computing performance by harnessing the power of the graphics processing unit (GPU)…CUDA-capable GPUs have hundreds of cores that can collectively run thousands of computing threads.”
Contrast that number with the typical Intel or AMD chip, which has 4 or 8 cores.
To recall, finding the solution to a neural network means to apply different coefficient (weights) to each input variable, make a prediction, then see how accurate that prediction is. Then, using the gradient descent algorithm, we try different coefficients and repeat the process. You keep doing that over and over until you reach the point where the neural network most accurately predicts whatever is is supposed to predict. With a large neural network of many thousands of sigmoids (nodes) that can take days.
To further make this simpler to understand, the neural network is represented as a series of inputs X weights W and a bias B, where X, W, and B are matrices. This yields an output, which is typically a small vector of says [0,1,2,3,4,5,6,7,8,9], as in the case of handwritten digit recognition. So we have:
X * W + B
X * W is the dot-product of 2 n-dimensional matrices. For example, for 2 dimensional matrices ,X and W, that is shown below where X is the first matrix, W is the 2nd, and X * W is the dot product. The dot product is the sum of multiplication of each corresponding row-column combination:
| X = [x11, x12, x13, x21, x22, x23, x31, x32, x33] | W = [w11, w12, w13, w21, w22, w23, w31, w32, w33] | X * W = [ (x11 * w11) + (x12 * w21) + (x13 * w31) … |
Which is more easily visualized in this graphic from Math is Fun:
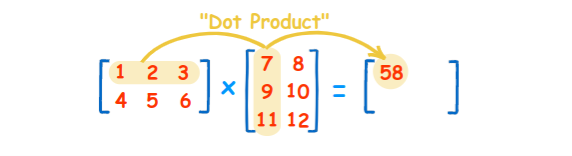
This can be done in parallel since it does not matter which row-column combination you pick first and you can work on all of those at the same time. That massively parallel operation is what GPUs are designed to do.
Doing this multiplication is simple for small matrices. But for large ones it takes much more memory and computing time, which is why using an additional processor makes sense.
Large matrices will even fill up the memory of the computer, a problem that can be solved by setting up machine learning libraries, like TensorFlow, to run in a cluster.
Where can you Run CUDA?
Not all software can run on GPUs since at a low level they operate differently than CPUs. What NVIDIA has done is provide an API to low level languages, like C++, that lets programs written in C++ use the GPU.
There is a special version of TensorFlow that you can easily install to take advantage of that. But that is made more complex because not all operating systems support CUDA, and virtual machines usually do not.
To install TensorFlow GPU version using virtualenv you follow the rather simple instructions here. For example, you install it using pip:
pip install --upgrade tensorflow-gpu
But first you must follow these instructions to install the Nvidia GPU toolkit.
Like I said, it will not work everywhere. For example, it works on Ubuntu but not Debian. And in general it does not work on virtual machines. The reason for that is the VM Is running on a hypervisor, which is responsible for low-level I/O. The VM does not have access to low level graphics.
To illustrate, here is how you check on Linux to see if you have a Nvidia graphics chip (or card. The cards are popular with gamers.):
lspci | grep -i nvidia 01:00.0 VGA compatible controller: NVIDIA Corporation GK107M [GeForce GT 650M] (rev a1) Kernel driver in use: nouveau Kernel modules: nouveau
This command shows that I have a CUDA-enabled GPU since it is listed in the Nvidia list of supported devices.
But if I run the same command on an Ubuntu server running in the cloud I get:
pcilib: Cannot open /proc/bus/pci
lspci: Cannot find any working access method
And it I leave off the grep filter and run this on a CentOs VM in the cloud I get a list of devices, but none of them are the Nvidia graphics card:
00:00.0 Host bridge: Intel Corporation 440BX/ZX/DX - 82443BX/ZX/DX Host bridge (rev 01)
00:01.0 PCI bridge: Intel Corporation 440BX/ZX/DX - 82443BX/ZX/DX AGP bridge (rev 01)
00:07.0 ISA bridge: Intel Corporation 82371AB/EB/MB PIIX4 ISA (rev 08)
00:07.1 IDE interface: Intel Corporation 82371AB/EB/MB PIIX4 IDE (rev 01)
00:07.3 Bridge: Intel Corporation 82371AB/EB/MB PIIX4 ACPI (rev 08)
00:07.7 System peripheral: VMware Virtual Machine Communication Interface (rev 10)
00:0f.0 VGA compatible controller: VMware SVGA II Adapter
00:10.0 SCSI storage controller: LSI Logic / Symbios Logic 53c1030 PCI-X Fusion-MPT Dual Ultra320 SCSI (rev 01)
00:11.0 PCI bridge: VMware PCI bridge (rev 02)
So if you want to experiment with this you can install CUDA on your notebook and desktop and try to multiply try matrices (in this case vectors and TensorFlow) like this:
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
The Instructions for doing that are here.
And if you really want to scale up this you can buy multiple Nvidia graphics cards and plug them into a desktop and multiple desktops and run a TensorFlow cluster across that.






