
Object storage is coming to the mainframe. It’s the optimal platform for demanding backup, archive, disaster recovery (DR), and big-data analytics operations, allowing mainframe data centers to leverage scalable, cost-effective cloud infrastructures.
For mainframe personnel, object storage is a new language to speak. It’s not complex, just a few new buzzwords to learn. This paper was written to introduce you to object storage, and to assist in learning the relevant terminology. Each term is compared to familiar mainframe concepts. Let’s go!
What is Object Storage?
Object storage is a computer data architecture in which data is stored in object form – as compared to direct-access storage devices (DASD), file/NAS (network-attached storage) storage and block storage. Object storage is a cost-effective technology that makes data easily accessible for large-scale operations, such as backup, archive, DR, and big-data analytics and business intelligence (BI) applications. IT departments with mainframes can use object storage to modernize their mainframe ecosystems and reduce dependence on expensive, proprietary hardware, such as tape systems and virtual tape libraries (VTLs).
Basic terms
Let’s take a look at some basic object storage terminology (and compare it to mainframe lingo):
- Objects. Object storage contains objects, which are also known as blobs. These are analogous to mainframe data sets.
- Buckets. A bucket is a container that hosts zero or more objects. In the mainframe realm, data sets are hosted on a volume – such as a tape or DASD device.
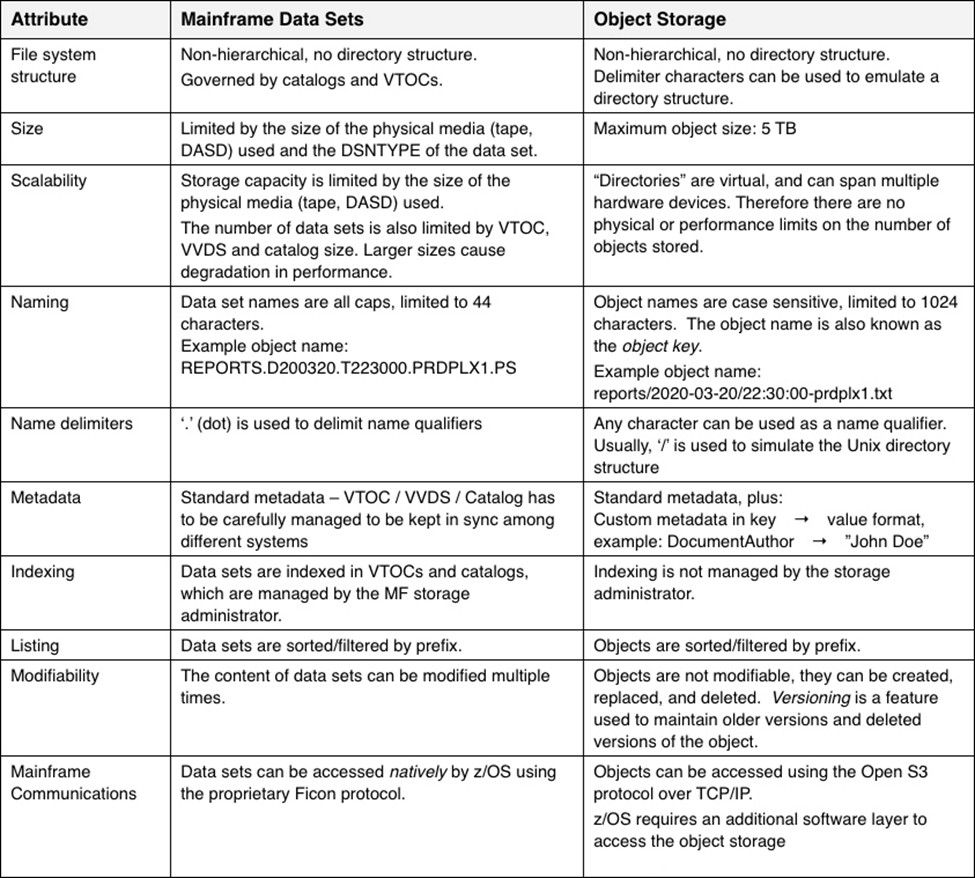
Data sets vs. objects – a closer look
As with data sets, objects contain both data and some basic metadata describing the object’s properties, such as creation date and object size. Here is a table with a detailed comparison between data set and object attributes:
NOTE: The object attributes described below are presented as defined in Amazon Web Services (AWS) S3 storage systems.
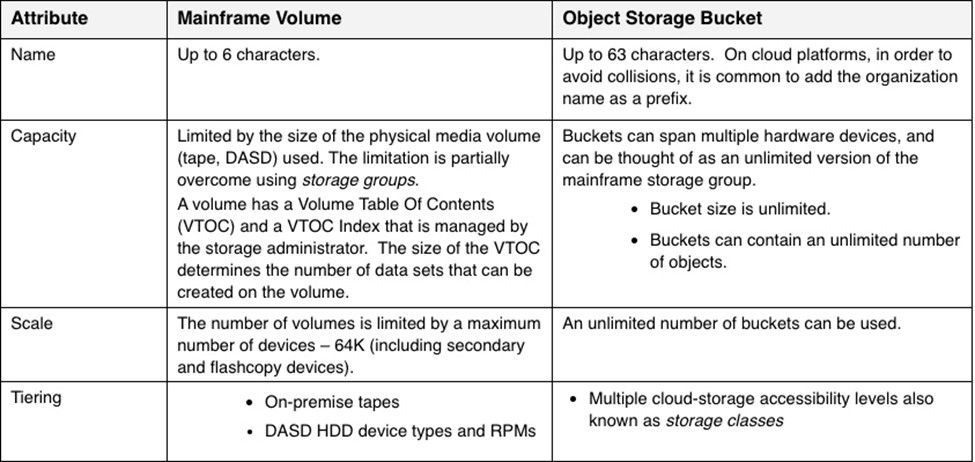
Volumes vs. buckets – a closer look
Buckets, which are analogous to mainframe volumes, are unlimited in size. Separate buckets are often deployed for security reasons, and not because of performance limitations. A bucket can be assigned a life cycle policy that includes automatic tiering, data protection, replication, and automatic at-rest encryption.
NOTE: The bucket attributes described below are presented as defined in AWS S3 storage systems.
Security considerations
In the z/OS domain, a system authorization facility (SAF) username and password are required, as well as the necessary authorization level for the volume and data set. For example, users with ALTER access to a data set can perform any action – read/write/create/delete.
In object storage, users are defined in the storage system. Each user is granted access to specific buckets, prefixes, objects, and separate permissions are defined for each action, for example:
- PutObject
- DeleteObject
- ListBucket
- DeleteObjectVersion
In addition, each user can be associated with a programmatic API key and API secret in order to access the bucket and the object storage via a TCP/IP-based API. When accessing data in the cloud, HTTPS is used to encrypt the in-transit stream. When accessing data on-premises, HTTP can be used to avoid encryption overhead. If required, the object storage platform can be configured to perform data-at-rest encryption.
Disaster recovery considerations
While traditional mainframe storage platforms such as tape and DASD rely on full storage replication, object storage supports both replication and erasure coding. Erasure coding provides significant savings in storage space, as the data can be spread over multiple geographical locations. For example, on AWS, data is automatically spread across a minimum of 3 geographical locations, thus providing multi-site redundancy and disaster recovery from anywhere in the world. Erasure-coded buckets can also be fully replicated to another region, as is practiced with traditional storage. Most object storage platforms support both synchronous and asynchronous replication.
Connecting object storage to the mainframe
BMC AMI Cloud Data is a software-only platform that leverages powerful, scalable cloud-based object storage capabilities for data centers that operate mainframes.
The platform runs on the mainframe’s zIIP processors, providing cost-efficient storage, backup, archive, and recovery functionalities with an easy-to-use interface that requires no object-storage knowledge or skills.






