Let us know how we can help
Sales & Pricing
Speak to a rep about your business needs
Help & Support
See our product support options
General inquiries and locations
Contact us
What Is Data Extraction? Definition, Tools & Methods
Fundamental to data management, data extraction consolidates data for subsequent analysis and informed decision-making.
BMC Tools with Data Extraction Capabilities

Control-M
Comprehensive data pipeline orchestration is just one powerful capability that keeps your business running smoothly, giving you confidence at every step.
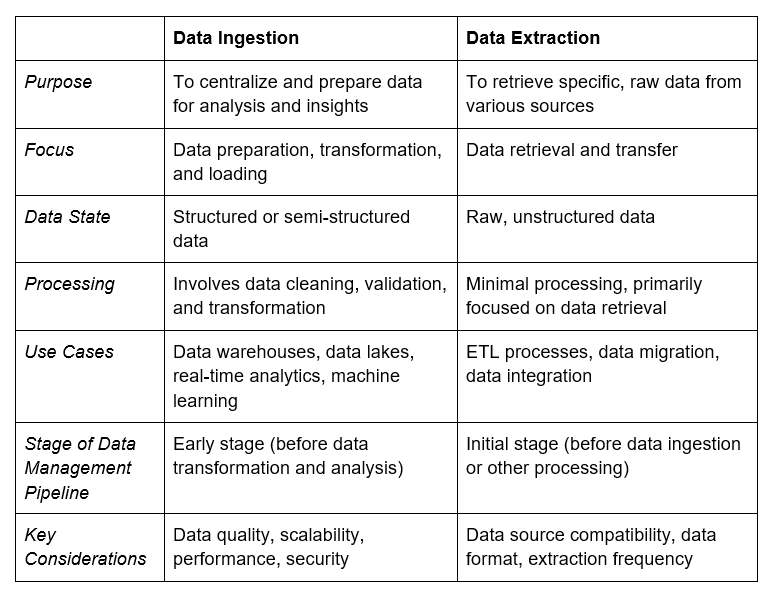
Learn moreWhat is the difference between data ingestion vs. data extraction?
Data extraction involves retrieving specific, raw data from disparate sources (e.g., spreadsheets, sensors, transactional systems) ahead of processing and utilization.
Data ingestion centralizes and prepares datasets for different applications, with the goal of creating actionable insights (e.g., reports, real-time data consolidation).
Types of Big Data Extraction Tools
ETL Tools
Automated solutions that streamline the extraction, transformation, and loading of data, improving efficiency and data quality.
Batch Processing Tools
Efficient tools designed to extract large volumes of data in scheduled batches, optimizing resource utilization and minimizing system impact.
Open-Source Tools
Customizable and cost-effective tools that require technical expertise to implement and maintain, offering flexibility and community support.
Process
What is the data extraction process?
Step 1: Validate Data and Clean Data Regularly
Step 2: Identify and Locate the Data to Extract
Step 3: Identify Data Changes
Step 4: Determine Where to Store the Data
Step 5: Initiate the Data Extraction Process
Step 6: Continue with a Comprehensive Data Management Plan
Step 7: Document, Test, and Audit Regularly
Step 1: Validate Data and Clean Data Regularly
Step 2: Identify and Locate the Data to Extract
Step 3: Identify Data Changes
Step 4: Determine Where to Store the Data
Step 5: Initiate the Data Extraction Process
Step 6: Continue with a Comprehensive Data Management Plan
Step 7: Document, Test, and Audit Regularly
Resources
Topics Related to Data Extraction
Data Extraction and ETL
Discover how data extraction, the first step in the ETL process, unlocks the power of your data and sets the stage for informed decision-making.
Learn moreA Big Introduction to Big Data
Understand the 3V’s of big data, its core concepts, and the latest big data trends in business so you stay in-the-know.
Learn moreBig Data: A Big Introduction
Understand the 3V’s of big data, its core concepts, and the latest big data trends in business so you stay in-the-know.
Learn more