Let us know how we can help
Sales & Pricing
Speak to a rep about your business needs
Help & Support
See our product support options
General inquiries and locations
Contact us
DataOps Explained
Understand how DataOps leverages analytics to drive actionable business insights
What is DataOps?
Short for data operations, DataOps is a practice that applies agile engineering and DevOps best practices in the field of data management to better organize, analyze, and leverage data to unlock business value. It's a collaboration between DevOps teams, data engineers, data scientists, and analytics teams to accelerate the collection and implementation of Data-Driven Business insights.
Central to the success of DataOps is automating and orchestrating data pipelines. Manual efforts alone cannot keep pace with the amount of data generated. Automation and orchestration enable:

Quick and efficient movement of data between various systems

Optimization of the health and performance of the data pipeline
Drivers for DataOps
Many companies struggle to organize and leverage their data to create value. Here's why:
 |
Rapidly increasing data sources, due to newer types of data or more complex business models, that make simplification difficult |
 |
Inadequate collaboration and business involvement that fail to drive a successful cultural shift |
 |
Unclear approach to measuring success, particularly for foundational initiatives, since many benefits are observed in other teams’ performance |
 |
Process mismatch, wherein traditional data management processes and practices do not align well with newer techniques such as artificial intelligence (AI) |
 |
Challenges in operationalizing at scale with rapidly rising stakeholder expectations for speed, flexibility, timeliness, and customization of new capabilities |
DataOps goals
Using data correctly can enhance and even revolutionize the way organizations operate. But unfortunately, 88% of data goes unanalyzed, and only 15% of big data projects make it to production. DataOps aims to solve these problems by changing the way that teams collaborate around data and how it is deployed into action.

Up to 88% of data goes unanalyzed
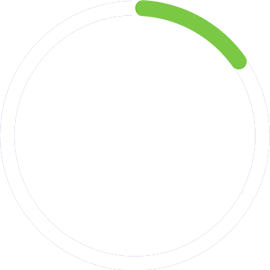
Only 15% of big data projects make it to production
How DataOps works
The core of DataOps is about harnessing quality data. When companies successfully do this, teams and leaders can deliver higher value and manage present and future risks with more confidence. Successful DataOps initiatives require the following:
Automation

Communication and collaboration

Culture

Automation
Communication and collaboration
Culture
BMC’s approach to DataOps
At BMC, we know that the modern business landscape presents teams and leaders with a growing list of challenges and problems to solve. Learning to harness your data is critical to evolving and staying competitive in an ever-shifting, disruptive world.
As the industry leader in data orchestration, we have an extensive history of empowering companies to become a Data-Driven Business. Our solutions are built to support the complex environments that span your entire ecosystem—from cloud to on-premises data centers to edge and everywhere in between.
BMC brings unique value to DataOps by:
- Delivering enterprise-scale orchestration of data pipelines
- Providing end-to-end visibility and predictive service level agreements (SLAs) across any data technology or infrastructure
- Enforcing governance and compliance rules in production while ensuring a frictionless experience for technical users
With portfolio solutions like Control-M, Control-M Python Client, and BMC AMI Data, you can simplify even the most complex data pipelines, enable data scientists to create better workflows, and leverage your data to its fullest potential.